Build Your Own Bitcask
This challenge is to build your own Bitcask. Bitcask is a log-structured hash table for fast key/value data storage and retrieval. Bitcask is the default storage backed for the Riak key-value store.
The creators of Riak describe Bitcask as “A log-structured hash table for fast key/value data”. What does that mean? It means that Bitcask writes data to an append-only log file and uses an in-memory hash table to keep track of the positions of its log entries. They chose this approach as it provides high read/write throughput and is relatively easy to implement and reason about.
Their specific technical goals were:
- Low latency per item read and write.
- High throughput, especially when writing an incoming stream of random items.
- The ability to handle datasets much larger than RAM without performance degradation.
- Crash “friendly”, meaning it provides fast recovery and zero to minimal data loss.
- Easy to backup and restore.
- A relatively simple, understandable (and thus supportable) codebase and data format.
- Predictable behaviour under heavy access load or large data volume.
You can read more about Bitcask in the Bitcask paper.
The Challenge - Building A Bitcask Implementation
In this coding challenge you’re going to implement Bitcask as a library and build a command line tool that allows you to set, get and delete keys as well as initiating a merge. If you’re wondering a merge is the term they chose to represent compacting the Bitcask log files.
A Bitcast database is simply a directory and the files in it. That makes it nice and easy to back and restore, simply copy the directory backup and back from the backup to restore.
Only one Bitcask process (the database server) can be accessing the database at a time. Within the directory only one of the files is active at a time. The current log file is the active file. When the active file reaches a specific file size it is closed and a new active file created. All files other than the active file are consider immutable.
Step Zero
In this step you’re going to set your environment up ready to begin developing and testing your solution. Please setup your IDE / editor of choice and programming language of choice for building command line tools. If you’re feeling adventurous, plan to add some networking - it seems many people commonly implement the ability to set and get keys using the Redis Serialisation Protocol (RESP) to build a server.
You can learn more about RESP in the build your own Redis server coding challenge.
Step 1
In this step your goal is to create a simple command line tool that will allow the user to set and get values from the hash table. You should write the hash table out to file after every update, overwriting all the existing entries. On startup your code should read the file and create an in memory datastore.
The file you write should be simple, looking something like this:
Key:Value
Key2:Value2
It’s a placeholder to get you started, you’ll evolve the design as you progress through the steps.
Having completed this step, your tool should support something like this:
% ./ccbitcask -db ./database set Key Value
% ./ccbitcask -db ./database get Key
Value
%
Here the -db flag lets the program know where to find the database file. I’d suggest it takes directory as an argument and then looks for a file called cask.0 within that directory.
Step 2
In this step your goal is to begin writing the values to the log file. The log file is an append-only file (AOF) where each entry is written in the following format:

The first field is the Cyclic Redundancy Check (CRC). If you’re not familiar with CRCs they’re error-detection codes often used in networking and storage devices to detect accidental or erroneous changes to data. Bitcask uses CRCs for precisely this reason, to check on startup that a record is valid (i.e. it’s not a corrupt partial record created during a crash).
It’s not clear from the paper, but I believe the CRC used is CRC-32, which you can learn about on the CRC page of Wikipedia. Wikipedia also has an example of the CRC-32 algorithm on the computation of CRCs page.
To calculate the CRC, first pack the other fields into an array of bytes*, then calculate the CRC using that array of bytes as an input. Once you have the CRC write the CRC followed by the array into the log file. As the log file is append only, each new record should be written at the end of the file.
*Again it’s not specified in the document, but I believe the bytes are most likely to be stored in little endian.
If, having written the new entry to the file the file size exceeds a preconfigured size, the file should be closed and a new one opened. For testing you might like to make the size quite low, i.e. a few hundred bytes. For a ‘production’ system it should be considerably larger. By default Riak uses 2GB.
You could use TDD to check the code you’re building does the right thing, or dig into the produced files with a tool like xxd. If you’re not familiar with xxd you can learn more in the build your own xxd coding challenge.
Step 3
In this step your goal is to update the hash table to refer to the log file. When Bitcask does this it stores some metadata in the hash table instead of the value. That metadata looks like this:
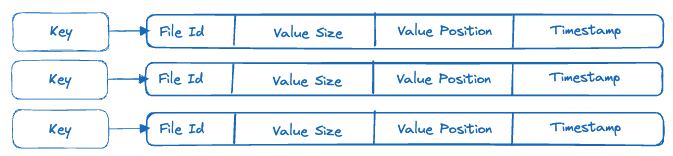
To complete this step, update your Bitcask implementation to write the metadata when setting values.
Step 4
In this step your goal is to use the metadata to read the values from the log file. The metadata is used to look up the value entry for a key in the relevant log file, the file id tells Bitcask which log file the value is in, the value position allows Bitcask to seek directly to the start of the value and then read value size bytes to get the value.
Test your code by doing what we did earlier:
% ./ccbitcask -db ./database set Key Value
% ./ccbitcask -db ./database get Key
Value
%
Be sure to set enough keys to spread the values over multiple files, then to test that the key is fetched. If you haven’t already, make sure that when a key is updated a new log file entry is written and the metadata is updated to reflect the new entry.
Step 5
In this step your goal is to implement deletion of keys. Bitcask handles deletion by writing a special tombstone value to the entry in the hash table and on disk. As far as I can tell this was done by setting the timestamp to the removal time, the value position, value size and file id to the max value for each type.
To complete this step, implement support for a delete command, and update the code to set the tombstone value for the supplied key. Then update the get command not return any deleted key. For example:
% ./ccbitcask -db ./database set Key Value
% ./ccbitcask -db ./database get Key
Value
% ./ccbitcask -db ./database del Key
% ./ccbitcask -db ./database get Key
(nil)
%
Step 6
In this step your goal is to implement the merge functionality of Bitcask. Merging, as Bitcask calls it, is the process of tidying up log files that no longer contain any live data values. Without this process the server’s disk would fill up and eventually run out of space.
Bitcask does the merging in a background task. This task iterates over all the non-active files and produces a new set of files containing only the live version of each key. As an aid to rapid startup it also creates a hint file alongside each of these files. The hint file contains the timestamp, key size, value size, value position and key of each item in the file. Reading the hint file will allow a new Bitcask server to rapidly rebuild the hash table on startup, providing a fast startup/recovery.
Once a file has been processed by the merge task it can be deleted, freeing up disk space and compacting the storage used.
You now have the necessary bits in place to implement the rebuilding of the hash table on startup. You can use the CRC to verify the validity of each record in the active file, discarding any that were incomplete/corrupted by a previous shutdown/crash.
Going Further
If you’d like to take this project further, consider making a network server for your Bitcask database and support a protocol such as RESP for getting, setting and deleting keys.
Help Others by Sharing Your Solutions!
If you think your solution is an example other developers can learn from please share it, put it on GitHub, GitLab or elsewhere. Then let me know - ping me a message on the Discord Server, via Twitter or LinkedIn or just post about it there and tag me. Alternately please add a link to it in the Coding Challenges Shared Solutions Github repo.
Get The Challenges By Email
If you would like to receive the coding challenges by email, you can subscribe to the weekly newsletter on SubStack here: