Build Your Own Rate Limiter
This challenge is to build your own API rate limiter.
Rate limiters are a key part of building an API or large scale distributed system, they help when we wish to throttle traffic based on the user. They allow you to ensure that one or more bad actors can’t accidentally or deliberately overload the service.
A rate limiting strategy can make your API more reliable, when:
- A user is responsible for a spike in traffic, and you need to stay up for everyone else.
- A user is accidentally sending you a lot of requests.
- A bad actor is trying to overwhelm your servers.
- A user is sending you a lot of lower-priority requests, and you want to make sure that it doesn’t affect your high-priority traffic.
- Your service is degraded, and as a result you can’t handle your regular traffic load and need to drop low-priority requests.
The Challenge - Building Your Own Rate Limiter
There are 6 common approaches to rate limiting:
- Token bucket - tokens are added to a ‘bucket’ at a fixed rate. The bucket has a fixed capacity. When a request is made it will only be accepted if there are enough tokens in the bucket. Tokens are removed from the bucket when a request is accepted.
- Leaky bucket (as a meter) - This is equivalent to the token bucket, but implemented in a different way - a mirror image.
- Leaky bucket (as a queue) - The bucket behaves like a FIFO queue with a limited capacity, if there is space in the bucket the request is accepted.
- Fixed window counter - record the number of requests from a sender occurring in the rate limit’s fixed time interval, if it exceeds the limit the request is rejected.
- Sliding window log - Store a timestamp for each request in a sorted set, when the size of the set trimmed to the window exceeds the limit, requests are rejected.
- Sliding window counter - similar to the fixed window, but each request is timestamped and the window slides.
In this challenge we’re going to implement the token bucket, fixed window counter, and sliding window counter, then we’re going to enable the rate limiting to work across several servers using Redis.
Step Zero
In most programming languages (Fortran and COBOL are exceptions) we index arrays from the element zero onwards because arrays are represented as a pointer to the beginning and an offset from that beginning - i.e. if you’re familiar with C then array[index] is equivalent to *(array + index).
As usually, I’ll leave you to setup your IDE / editor of choice and programming language of choice. Once you’re set up, let’s proceed to Step 1.
You might also want to download and install Postman for the later parts of the challenge. If not you can use curl.
Step 1
In this step your goal is to implement a simple API you we can use for testing. For this challenge I’d like you to create two endpoints: /limited and /unlimited.
You can have them return anything you want, for my examples I’ve had them return some text, here is my test to check they work, you should do something similar:
% curl http://127.0.0.1:8080/unlimited
Unlimited! Let's Go!
% curl http://127.0.0.1:8080/limited
Limited, don't over use me!
Step 2
In this step your goal is to implement the token bucket algorithm for rate limiting. The token bucket algorithm works like this:
- There is a ‘bucket’ that has capacity for N tokens. Usually this is a bucket per user or IP address.
- Every time period a new token is added to the bucket, if the bucket is full the token is discarded.
- When a request arrives and the bucket contains tokens, the request is handled and a token is removed from the bucket.
- When a request arrives and the bucket is empty, the request is declined.
For this step, implement this strategy such that the bucket is per IP address, has a capacity of 10 tokens with new tokens added at a rate of 1 token per second.
When a request is rejected you should return the HTTP status code of 429 - Too Many Requests.
Once you have implemented that you can use Postman to test it. There is a blog post that introduces the performance testing abilities of Postman and explains how to set it up here.
I configured a test to hit the limited API endpoint with 10 Virtual Users, as you can see that results in no errors initially, (the bucket had ten tokens, then after a second 90% of the requests fail as there are 10 users trying to access the API, but only one token being added per second.
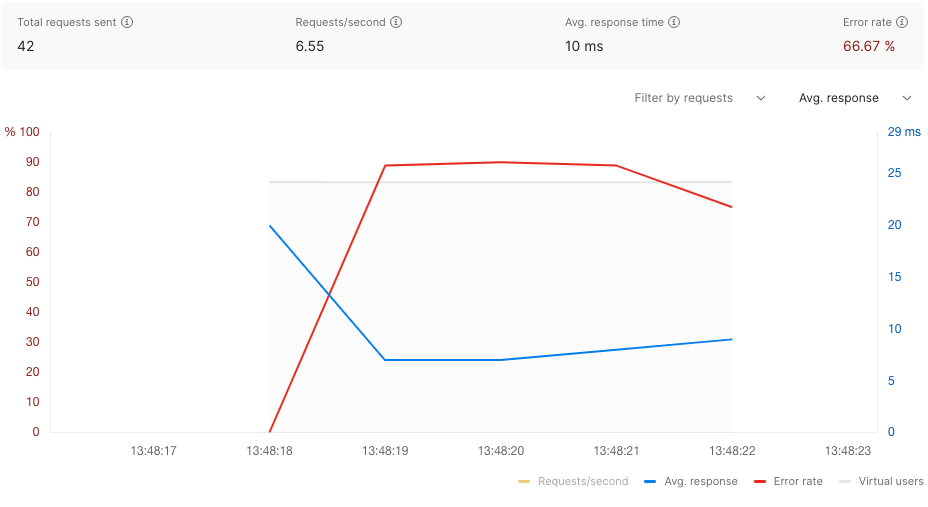
Once that works, on to Step 3.
Step 3
In this step your goal is to fixed window counter algorithm. The fixed window counter algorithm works like this:
- A window size of N seconds is used to track the request rate. Each incoming request increments the counter for the window.
- If the counter exceeds a threshold, the request is discarded.
- The windows are typically defined by the floor of the current timestamp, so 17:47:13 with a 60 second window length, would be in the 17:47:00 window.
Again you can use Postman to test this, I used 10 Virtual Users with a 60 second window and 60 request threshold. You can see the distinct pattern of requests succeeding just after the window changes followed by a number of rejections.
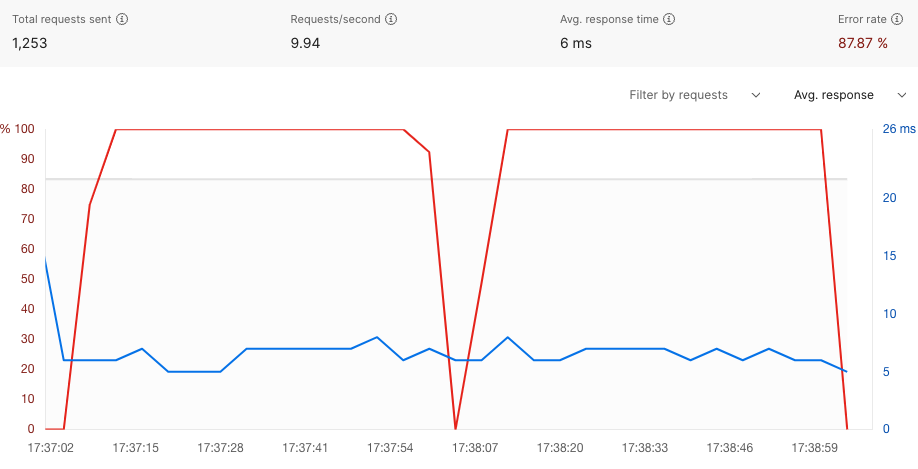
Step 4
In this step your goal is to implement the sliding window log algorithm. The sliding log algorithm involves:
- Tracking a time stamped log for each consumer request. These logs are usually stored in a hash set or table that is sorted by time.
- Logs with timestamps beyond a threshold are discarded.
- When a new request comes in, we calculate the sum of logs to determine the request rate.
- If the request when added to the log would exceed the threshold rate, then it is declined.
The advantage of this algorithm is that it does not suffer from the boundary conditions of fixed windows. The limit will be enforced precisely and because the sliding log is tracked for each consumer, you don’t have the issue that every use can suddenly surge in requests each time a fixed window boundary passes.
The disadvantage is that it needs to store an unlimited number of logs for every request. As the size of the logs grows it can become expensive to compute the summation over all the log entries. As a result it does not scale well to handle large bursts of traffic or denial of service attacks.
I’ll leave you to define your own test for this one as designing tests is also a key skill to learn as a software engineer. It would be a great example to experiment with TDD on if you’re not already doing that.
Step 5
In this step your goal is to implement the sliding window counter algorithm. It is a hybrid approach that combines the low processing cost of the fixed window algorithm, and the improved boundary conditions of the sliding log algorithm.
- Like the fixed window algorithm, we maintain a counter for each fixed window. But we will need to store the current and the previous windows counts.
- We use a weighted count of the current and previous windows counts to determine the count for the sliding window. This helps smooth out the impact of burst of traffic. For example, if the current window is 40% through, then we weight the previous window’s count by 60% and add that to the current window count.
As this algorithm stores relatively little data it suitable for scale, including scaling across distributed clusters.
Again the final challenge of this step is to design a test for your rate limit calculation.
Step 6
In this step your goal is to extend your sliding window counter rate limiting to work across multiple servers. You can use a database like Redis to store the count for the requests and have each server update the database so the rate limiting is shared across two or more servers.
To test this run two (or more) servers each on a different port then verify that you can make the full allowance of request between the servers. You could for example limit the client to 60 requests per minute, send all 60 to one server in a couple of seconds with Postman and then use curl to hit the other server and verify the request is rejected.
If you want to take this even further you could develop your own application load balancer to sit in front of the servers and use your own Redis clone to provide the shared database - extending this to incorporate three Coding Challenges!
Help Others by Sharing Your Solutions!
If you think your solution is an example other developers can learn from please share it, put it on GitHub, GitLab or elsewhere. Then let me know - ping me a message on the Discord Server, via Twitter or LinkedIn or just post about it there and tag me. Alternately please add a link to it in the Coding Challenges Shared Solutions Github repo.
Get The Challenges By Email
If you would like to receive the coding challenges by email, you can subscribe to the weekly newsletter on SubStack here: